弊社エンジニア2名が福岡Ruby会議02前夜祭でLTをしてきました
こんにちは、発表のときは緊張してつい早口になりがちなうなすけです。
さて、11/25に福岡Ruby会議02が開催されました。その前日に、pixivさん主催の前夜祭が開催され、そこで弊社のエンジニア2名がLTをしてきました(もちろん、費用は全て会社負担です!)。この記事は、それを含む福岡訪問の全体的な感想記事になります。
前夜祭LT
「Ruby on Rails on ECS」 うなすけ

まずは僕、うなすけの発表です。発表内容としては、過去にこのブログに書いた以下2つの記事のまとめになっています。
blog.spicelife.jp blog.spicelife.jp
10分間で話すには詰め込みすぎて、始終早口でまくし立ててギリギリ収まったという感じでした。
「普段の生活の中で困っていることをRubyで解決している事例を中心にお話します」あそなす

猫を飼っているご家庭だと、「自分がいないときにウチの猫は何をしているんだろう」ということが気になるのは当たり前のことなのでしょうか?とにかく猫の様子を捉えることに対する熱意を感じる発表でした。
neko_chan = true
福岡Ruby会議 02
福岡Ruby会議02では、そのコンセプトとして「もう一度、Rubyと出会う」を掲げていることもあり、単なる技術的なトークに留まらない、Rubyに向きあう発表がほとんどで、どれも聞いていてとても面白く、また考えさせられるものでした。
特に松田明さんのKeynote 「Finding Ruby Again」では、RubyKaigiが何故開催されているか、どのようなCFPが採択されるのか、などの松田さんの想いが伝わってきて、是非とも次のRubyKaigiにも参加したいと思わされました。
福岡
福岡といえば、美味しいものが沢山ありますね。僕も「福岡に行く」とツイートしたら、福岡出身の友人達から続々とここに行け情報が共有されてきて驚きました。その中でも、印象に残っているものをいくつかピックアップしたいと思います。
博多らーめん ShinShin
前夜祭のいわゆる3次会?で行ったラーメン屋さんです。博多ラーメン特有の細麺で、僕は特にチャーシューがとても美味しいと感じました。甘味もあり、ホロリと崩れるチャーシューをもう一度食べてみたいものです。 また「もっちゃん」というもつ鍋の〆のちゃんぽんを再現したメニューもあり、こちらはスープの味が普通のラーメンとベースは同じなのに全然違った味わいで美味しそうでした。
天麩羅処ひらお
ここは福岡Ruby会議02の会場の真横にありましたが、お昼時などのそれっぽい時間はとても混雑します。なので当日に行くのはあきらめて、翌日の15時頃に行きました。しかしそれでも1時間くらい並びました。
とにかく回転を早くするためか、メニューにある天麩羅は揚げられたそばから目の前のバットに置かれていくというスタイルでした。揚げたてでとてもアツアツ、サクサクの天麩羅はめちゃくちゃ美味しかったです。
通りもん
言わずもがな、お土産には通りもんを買っていきました。通りもんは意味不明なくらい美味しいので、お土産用と、お土産に手を付けてしまわないために自分で食べる分を買いました。
まとめ
福岡Ruby会議03もいつか開催されるとのことなので、良い発表と行きそびれたグルメのためにも絶対行くぞという気持ちです!
STEERSのSSL/TLS証明書をACMのDNS Validationで発行したものに差し替えました

こんにちは。アドレスバーが緑色になっていると嬉しいうなすけです。
Symantec発行の証明書がChrome 70以降で信頼されなくなる
Webサービス開発者の皆さんは、開発者ツールを使ってWebサービスの挙動を詳しく見ることは日常的に行なっていることと思います。僕もそうです。 ある日、開発者ツールのconsoleにこのような警告が出ていることに気づきました。
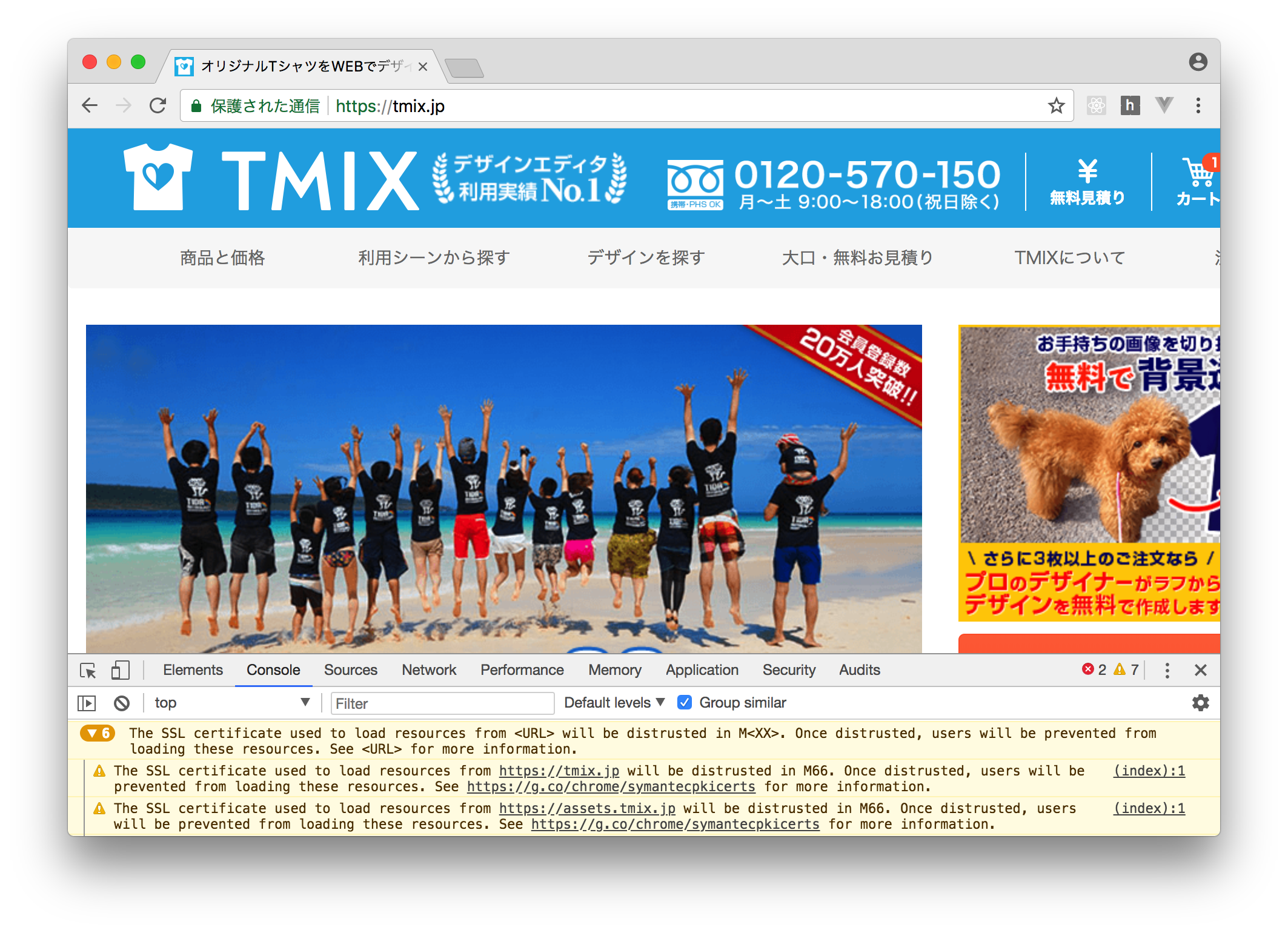 (記事公開時点で、TMIXではまだ同様の警告が確認できます)
(記事公開時点で、TMIXではまだ同様の警告が確認できます)
リンク先を詳しく読むと、Symantecにより発行されたSSL/TLS証明書がChrome70以降では信頼されなくなるということになっているようです。
これを回避するためには、Symantecによって2017年12月1日以降に発行されたSSL/TLS証明書を新たに取得するか、もしくはDigiCertなどの別の業者の発行するSSL/TLS証明書を取得するしかありません。
今回、STEERSは証明書の更新のタイミングが迫っていることもあり、SSL/TLS証明書発行業者を変えることにしました。
候補としてはDigiCertやGlobalSignなどいくつかあったのですが、元々の証明書がDV証明書であったこと、STEERSをAWSで運用していることからACM発行のものに切り替えることにしました。
ACMのDNS Validation
さて、ACMでSSL/TLS証明書を発行する際に行なわなければいけないドメインの所有確認ですが、これまではそれっぽいメールアドレスに送信されるURLに訪問して所有確認をする方式しか存在しませんでした。しかしつい先日、DNSにあるレコードを追加する形で所有確認する方式が追加されたので、それを使ってACMによるSSL/TLS証明書発行を行ないました。1
AWS Certificate Manager: Easier Certificate Validation Using DNS
us-east-1とap-northeast-1で証明書を発行する
STEERSでは、静的ファイルの配信にCloudFrontを使用しています。CloudFrontでACMにより発行されたSSL/TLS証明書を使用するには、ACMのregionがus-east-1である必要があります。また、STEERSのELBはap-northeast-1に所属しているので、STEERS全体のHTTPS化のためにはus-east-1とap-northeast-1の2つのregionのACMでSSL/TLS証明書を発行しなければなりません。
なので、まずはus-east-1のACMで証明書のリクエストをします。するとCNAMEに登録するサブドメインが指定されるので、それをRoute53に追加します。弊社ではroadworkerを使っているので、以下のような行を追加してapplyすることで作業は完了します。
rrset "hogehogefugafuga_domainkey.steers.jp", "CNAME" do ttl 3600 resource_records "hogehogefugafuga.dkim.amazonses.com" end
さて、同様にap-northeast-1でもACMから証明書のリクエストを行なうと……なんと、指定されるCNAMEはus-east-1で指定されるものとまったく同じものでした。なので、regionごとにCNAME recordを追加する必要はなく、そのままシュッと証明書が発行されました。便利!
発行したSSL/TLS証明書を使用する
あとはaws management consoleでポチポチやっていけば、CloudFrontとELBでACM発行のSSL/TLS証明書を使用するようになり、警告の出ない状態にすることができます。

https://www.ssllabs.com/ssltest/analyze.html?d=steers.jp&latest
まとめ
今回はSTEERSのSSL/TLS証明書を差し替えましたが、TMIXのSSL/TLS証明書の期限も迫ってきているので、同様にTMIXもACMによるSSL/TLS証明書を使用するようにするつもりです。
皆さんも自分の使っているSSL/TLS証明書が大丈夫なものか確認してみてはいかがでしょうか。
追記
17:04:25 誤字修正しました
TMIXをRails5にアップグレードした話

初めまして、心は永遠に新卒のエンジニア、undoです。 9月末、TMIXがrails5化(5.0系列最新の5.0.5化)されました。 そのときやったことやハマったことなどの覚え書きをしていこうと思います。
Rails5
歴史的経緯により、TMIXは複数のRailsアプリケーションが共通のRDBを参照しに行く構成になっています。 今回自分が行ったのは、そのうちtmix-webと呼ばれるアプリケーションで、ざっくりいえばお客様に直線触れていただくところがメインになります。 これ以外のTMIXに関連するアプリケーションは既にRails5へのアップデートが完了していましたが、一番大きなアプリケーションであり、複雑な箇所や他に依存している箇所が多いことで、Rails5化するまでに時間が掛かりました。
作業を始めたのは2017年8月某日、当時5.0系列で最新だった5.0.5にアップグレードする形にしました。
アップグレード手順
Rails4→Rails5ということで、仕様の変更など手間取るところが幾つかありました。 以下参考までに行った作業など。
RailsのGem update
- Gemfileのバージョンを5.0.5に書き換えます。
-gem 'rails', '4.2.9' +gem 'rails', '5.0.5'
- bundle updateコマンドを実行します。
$ bundle update rails
関連Gemのupdate
$ bundle update
rails5の設定に対応
$ rails app:update
ApplicationRecordをActiveRecordのモデルのベースクラスにする
Rails5 からは各 model は ActiveRecord::Base ではなく ApplicationRecord を継承するようになりました。それに合わせて修正していきます。
//app/models/application_record.rb class ApplicationRecord < ActiveRecord::Base self.abstract_class = true end
次に、各モデルクラスの継承関係を変更します。例えば
- class Hoge < ActiveRecord::Base + class Hoge < ApplicationRecord
この後は、落ちているテストを見ながら、Rails5化による仕様の変更などに対応していきます。以下覚え書きです。
skip_before_actionにraise: falseを追加
同一ファイル内にcallback関数がない場合、raiseオプションにfalseを設定しない場合、ArgumentErrorが出るように変更されました。
テスト用のgem rails-controller-testingを追加
controllerのテストで assigns などを使う場合は rails-controller-testing の gem が必要になりました。
./config/application.rb にAutoloadの許可を追加
Rails5からproduction環境でのみAutoloadが廃止になりました。 lib以下に定義している場合など、許可をしたい場合は以下の記述が必要になります。
config.enable_dependency_loading = true
Rails5で非推奨になったメソッドの変更
before_filterをbefore_actionに変更uniqをdistinctに変更render :textをrender :plainに変更render nothing: trueをhead :no_contentに変更 このへんはそのまま置き換えていけば大丈夫そうです。redirect_to: backをredirect_backに変更
redirect_to :back, notice: '入力されていない項目があります'
redirect_to を利用する場合は上記のようにオプションでメッセージを記述できましたが、redirect_backはどうやらできないようです。
redirect_back(fallback_location: root_path) flash[:notice] = '入力されていない項目があります'
諦めて別々に書きます。
Arelを使っているところの修正
軽く説明。ArelはActive Recordの内部で使用されるSQL生成ライブラリです。 Arelを使うと文字列でSQLを書くことなく、Rubyのコードとしてクエリを書くことが出来るという便利なものですが、ArelはRailsのプライベートAPIであるため、完全にサポートされていません。アップグレード時の保証がありません。
今回Rails5にアップグレードしたことで、そのArelを使っていたところが盛大に壊れてしまいました。 幸い、壊れた箇所はArelでなくとも問題ない箇所だったため、先輩がArelを使わない記述にリファクタリングしてくれました :smile:
RSpecの警告・仕様変更
上述した対処で動作はするようになりましたが、RSpecの仕様変更などによってテストが落ちている点がいくらかありました。
paramsがnilを受け取らなくなった
params: nilのように定義するとparams: ""として受け取るようです。
そのため
before { params.merge!(hoge: nil) }
のように記述していたところを
before { params.delete(:hoge) }
に書き換えました。またそれに合わせて該当Controllerの処理も書き換えました(nil?ではなくてpresent?に)
get、postなどで渡すパラメータの仕様変更
Rails5 からActionController::TestCaseが非推奨になったので、それに合わせて記述を変更します。
- get :callback, hoge: "fuga" + get :callback, params: { hoge: "fuga" }
だいたいこのへんでテストOKになりました。 他にもwarningを可能な限り潰していきました。
アップグレードを終えて
Rails 5 にすることで、様々な新機能が使用できるようになります。 お客様には直接関わりのないところですが、より開発しやすく、バグや脆弱性の少ない新しいバージョンにすることで、エンジニアとしてより良いサービスを作り続けられることに繋がると思います。 次は5.1系列へのアップグレードですね!
ridgepoleのapplyをECS RunTaskで実行するようにしました
おはようございます。冪等性が大好きなうなすけです。
さて、つい先日にridgepole applyをECS RunTaskを用いて行うようにしたので、今までどのようにapplyしていたのか、RunTaskにする過程でハマッたことなどを書いていこうと思います。
ridgepoleとは
ridgepoleは、Railsのmigrationと同様のDSLでデータベースのスキーマを管理できるコマンドラインツールです。どのようなものであるかは、cookpadさんの以下のブログに詳細が書かれています。
TMIXとridgepole
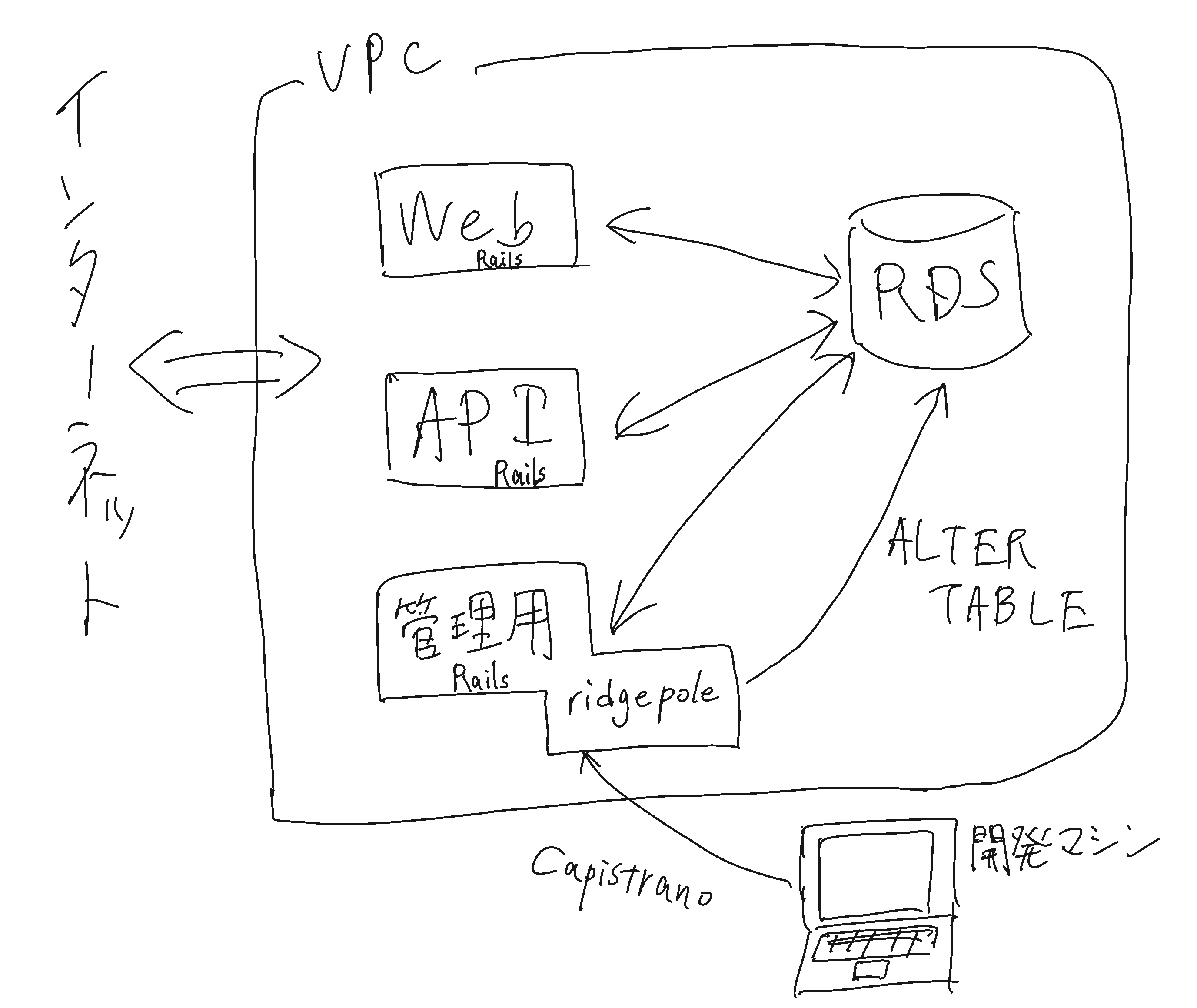
TMIXは、歴史的経緯により、複数のRails applicationが共通のRDBを参照しにいくという構成になっています。database schemaをridgepoleで管理するようになるまでは、複数のリポジトリ間で db/schema.rb のコピペを都度行なっていました。
ridgepoleのapplyについては、capistranoを用いて、アプリケーションの動作するインスタンスを間借りしてRDSに対してschema applyをするという形にしていました。理由としては、都度インスタンスを構築するのは面倒で複雑だし、schema apply用のインスタンスを起動したままにしておくのは無駄なコストが発生するためです。実際、この方法でのschema applyは後述する問題以外の不具合は発生することなく今まで動作していました。
簡単に構成を描いてみました。
インスタンス間借り方式の不具合
ある日のこと、schemaのapplyができなくなっていることに気づきました。Schemafileにtypoがまざっているというわけでもなく、開発用データベースへのapplyは正常にできるというのに、です。
原因は、間借りしているアプリケーションのサーバー側にありました。というのも、数日前にそのRailsアプリケーションの動作するRubyのバージョンを上げてしまっていたのです。その時にインスタンスを新規に作り直していたので、新しいバージョンのRubyのみが入っている状態になっていました。capistranoではdeployする際に指定されたバージョンのRubyを使用するように設定されているので、要求しているバージョンのRubyが存在せずdeployが失敗するようになってしまいました。
この問題については、ridgepoleで使用するRubyのバージョンをインスタンスにインストールされているものと揃えればいいだけ、と言ってしまえばそれまでです。
Docker化したときにどうするのか
また、今後TMIXのインフラをDocker化していくとなった場合には、いわゆる「Rubyがインストールされているインスタンス」というものが存在しなくなるため、今までのcapistranoを用いたschema applyは不可能になります。
ECSによるschema apply
前述の不具合と今後の懸念から、ECS RunTaskによるschema applyを行なうことにしました。では、ECS RunTaskによるschema applyのためには、どのような作業が必要になるでしょうか?
Docker imageの作成
まずは実行するためのDocker imageが無くては始まりません。一部加工しましたが、実際のDockerfileを以下に記載します。
localeをja_JP.UTF-8にしていますが、これは何故かというと、いくつかのcolumnのdefault値に日本語の文字列が含まれているため、schema applyのときにridgepoleがinvalid multibyte charで落ちてしまうためです。
CMDがridgepole --applyではなく独自のRake taskになっているのは、schemaのapply結果を社内チャットツールに投稿するためです。
FROM ruby:2.4.1-slim
WORKDIR /var/schema
RUN apt update \
&& apt install -y \
gcc \
libmysqlclient-dev \
locales \
make \
wget \
&& rm -rf /var/lib/apt/lists/*
# set locale to ja_JP.UTF-8
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
RUN echo ja_JP.UTF-8 UTF-8 > /etc/locale.gen \
&& locale-gen \
&& update-locale LANG=ja_JP.UTF-8 LC_ALL=ja_JP.UTF-8
COPY Gemfile /var/schema
COPY Gemfile.lock /var/schema
RUN bundle install
COPY . /var/schema
CMD bundle exec rake apply:$DATABASE_ENV
task definitionの作成
Docker imageができていれば、task definitionは悩むことなく簡単に作成できるでしょう。今回はproduction用とstaging用の2つのtask definitionを作成しました。
テストの実行
ただschemaの定義がされているリポジトリですが、もちろんテストは存在します。どのようなテストなのかというと、そのschemaが実際にapplyできるかどうか、ということを確認するものです。tableやcolumnの名前のtypoは防ぐことができませんが、DSLの文法が間違っていないかなどの確認をすることができます。
運用をDockerに寄せるのであれば、テストもDockerで行なうのが筋というものでしょうか。なので、CIで稼動するMySQLに対してridgepole --applyを実行する形式から、docker-composeでlinkしているMySQLのコンテナに対してridgepole --applyを実行する形式に変更しました。
ただ、手元のマシンで実行したり、CI上のMySQLに対して実行したりするのとは違い、docker-composeでの実行は、mysqldが上がってくる前にridgepole --applyを実行しようとして落ちてしまうこともあります。
そこでCIで実行するテストは、事前にdocker-compose up -d mysqlでMySQLのコンテナを立ち上げた後、mysqladmin pingが成功するまで数秒間隔のループを回すことにしてこの問題を解決しています。
Deployする
さて、本命のdeployについてです。deployは特定のbranchへのmergeがされた時に実行するようにしていますが、具体的に何をしているかというと……
- ridgepole applyを実行するDocker imageのbuild
- buildしたimageにcommit hashのtagを付けてECRにpush
- 今buildしたDocker imageのtagが指定されたtask definitionの作成
- 作成したtask definitionを用いてRunTaskの実行
となっています。Docker imageのbuildをmaster branchへのmergeのタイミングで実行していないのは、deploy用branchからはテストがpassしている最新のcommit hashがわからないためです。deploy branchは常にテストがpassしているmasterからmergeされるので、mergeされた時点でのcommit hashを用いることにしています。
(厳密に言えば、git rev-parse masterを実行すればmasterのcommit hashは判明しますが、deployのタイミングでCI側にgitがインストールされていないため、環境変数に設定されている現在のcommit hashを使用しています)
ECS RunTask化成功
deployが成功すると、前述したRake taskによってこのようなメッセージが投稿されます。これによって、ECS RunTaskでのdeployが成功したことが確認できました!
今後の課題
さて、schema applyのDocker化はつつがなく終えることができましたが、Docker化という意味ではまだ課題が残っています。その一番大きなものが、「schemaがapplyされているMySQLのDocker imageを作成する」というものです。なぜこれが必要なのかというと、TMIXを構成する各Rails applicationは、ridgepoleにschemaの運用を移譲した結果、db/schema.rbの中身が空なのです!
そのため、各Rails applicationでテストを実行したいときには、まずschema repositoryをcloneしてridgepole --applyを実行するようにしており、ここで大幅な時間がかかっています。そのため、schemaが適用されているMySQLのimageをpullしてこれれば時間短縮になるのですが、まだ手が出せていません。
まとめ
課題は山積みですが、この調子でどんどんコンテナ化をやっていきたいと思っています!
RailsアプリをECSで運用するまでにやったこと、これからしていくこと
おはようございます。一番よく使うemojiは 👀 (:eyes:) のうなすけです。
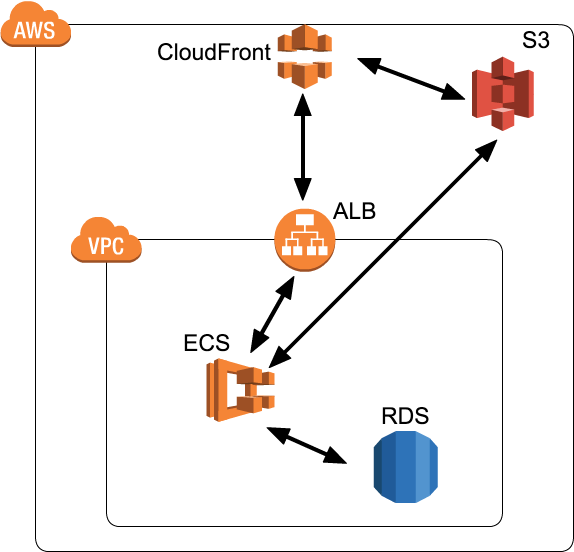
さて弊社では、最近社内Railsアプリをひとつ構築しました。それをECSで運用することにしたので、そこに至るまでの経緯、つまづき、これからの課題などなどを記事にしていこうと思います。上の図は現時点での簡単なAWS上での構成図です。
以下、見出しは時系列順でやったことを記録していきます。
社内Railsアプリ、一体どんなもの?
ここで新規に構築することになった社内Railsアプリですが、特に凝ったことはしていない単純なRailsアプリです。初めからECSで運用することにしていたので、開発環境も全てDockerで構築しています。Railsのバージョンは5.1.0、Docker imageのFROMにはruby:2.4.1-silmを採用しています。
Docker imageのtagについて
development環境のdocker imageですが、手元でbuild/pushさせるのは属人化しやすく、また継続的に実行したいので、CircleCIでbuildしてECRにpushすることにしました。そのときのimageのtagですが、push毎にgit commit hashをtagとして付与し、master branchでのbuildではそれに追加でlatestを付けることにしました。
これにより、「とりあえずlatestなら動く」という状況にしています。
共通部分を切り出し、production用のDockerfileをつくる
さて稼動させようかという状況になりましたが、この時点ではdevelopmentのDockerfileしかありませんでした。そこで、DRYになるように共通部分(OSのパッケージインストールなど)を切り出してbase imageとし、developmentとproductionはそれらをFROMにするDokerfileに分割することにしました。
app
config
db
docker/
└ app-base/
└ Dockerfile
└ app-development/
└ Dockerfile
└ app-production/
└ Dockerfile
ディレクトリ構造はこのような感じです。base imageはcontainer/baseにmergeされたときにbuild/pushを行なうようにしました。
assets配信どうする問題
production運用といえば、assetsの配信をどうするか、ということも当然考慮する必要があります。Dockerで運用をするとなれば、imageの少サイズ化も見込めるので、AssetSync/asset_sync を採用する場合が多いかと思います。
ですが僕達は、amakanの構成に倣って、assetsをcontainer内に含めることにしました。その思想については、id:r7kamura 氏の以下の記事に詳しく記載されているので、ここで詳細に述べることはしません。
リバースプロキシどうする問題
Railsアプリに限らず、Webアプリを運用していくとなるとアプリの前段に行ないたい処理は出てくるものです。主な処理としては以下が挙げられます。
スロークライアント対策、SSL/TLSの終端処理についてはALBを利用することで達成されます。また、静的ファイルの配信については先述のamakanと同様の構成(Railsによる配信 + CDN)にすることで達成されます。一度リバースプロキシは不要になるかと思われましたが、その他細かい要件として以下が挙げられました。
- HTTP → HTTPSへのリダイレクト
- Basic認証
- Cache-Control Headerの書き替え
- assets配信用ドメインでの/assets/*以外のアクセスに対して400系のレスポンスを返す
これらをRack middlewareで行うことも検討したのですが、アプリ層で行うべきではないと判断し、前段にNginxを設置することにしました。これが後に問題を引き起こすのですが……
app
config
db
docker/
└ app-base/
└ Dockerfile
└ app-development/
└ Dockerfile
└ app-nginx/
├ Dockerfile
└ nginx.conf
└ app-production/
└ Dockerfile
このNginxもDocker containerとして動作させ、その設定はアプリのリポジトリに含めることにしました。container/nginxにmergeするとbuild/pushが行なわれます。
Deployどうする問題
さあ、productionのimageもできましたし、Nginxの設定も終わりました。となると残すはDeployです。
この時点で、社内にはもうECS上で動くアプリがありましたが、それはNode.jsで動作するアプリであり、Deployもaws-sdk-jsを使用したJavaScriptによるスクリプトを実行するというもので、今回のRailsアプリでは同様の仕組みを利用することができません。
それに、今後TMIXやSTEERSをECSで運用することを視野に入れると、汎用的に使える新しい仕組みを構築したほうがよさそうです。
ECS Deploy tool選定
僕達がECS deploy toolに求める要件は、主に以下の4つでした。
- Service / Task Definition を一元管理する
- awslogs の設定等をインフラチームで管理したい
- Task Placement Constraints は Task Definition で管理する
- Task Placement Constraintsの変更によるServiceの作り直しを避けたい
- Service の Task Definition や Task Definition の Image はコードで管理せず、外部パラメータを用いて更新できるようにする
- 環境を問わずデプロイできるようにする
そして、ECSのdeploy toolというと、これらが挙げられるでしょう。
- eagletmt/hako: Deploy Docker container
- silinternational/ecs-deploy: Simple shell script for initiating blue-green deployments on Amazon EC2 Container Service (ECS)
- aws/amazon-ecs-cli
これらを触ってみて、自分達の要件に合うかどうか調査して……自前で実装することに決めました。

それが、こちらになります。
このgemを使い、あるひとつのリポジトリで全てのアプリのTask DefinitionとServiceの定義を含むDocker imageを作成し、Deployはdocker execすることによって実現させる、という風にしました。
まだまだ扱いはWIPなgemですが、そろそろversion 1.0をリリースしたい気持ちはあります。
db:migrateができない問題
database schemaを変更した際には、deploy前にdb:migrateを実行してやらなければなりません。
しかし、ECSのRunTask経由で実行すると、なぜかbundle exec rails db:migrateは実行できず(SIGTERMで死ぬ)、試行錯誤の結果/bin/sh -c bundle exec rails db:migrateだと実行できることがわかりました。
これについてAWSのサポートに問い合わせたところ、同Taskで動作しているNginx contaierがすぐに落ち(何もさせないようtrueを実行するようにしていた)、Task Definitionにessential: trueを指定しているためにそれに引き摺られてRailsのcontainerも落ちる、という動作になっていることが判明しました。
これについては、RunTask用にNginxを含まないTask Definitionを用意し、それを使用することで回避しました。Nginxの存在によって構成が複雑になってしまっているため、本来アプリ層でやるべできはないことをアプリ層でやることとのトレードオフですが、NginxをやめてRack middlewareを使用することでTask Definitionの二重管理をやめることを検討しています。
ログが見たいけどCloudWatch Logsは面倒
Railsのログは、STDOUTに吐いて、それをawslogs log driverでCloudWatch Logsに保管しています。これでは手元でgrepやawsを使ったログの解析ができません。
この問題は、現在実行中のコンテナのログを取得する次のようなscriptを作成することで解決しました。(一部省略しています)
#!/usr/bin/env ruby require 'aws-sdk' ecs = Aws::ECS::Client.new cwlogs = Aws::CloudWatchLogs::Client.new service = ecs.describe_services(cluster: CLUSTER, services: [SERVICE]).services.first deployment = service.deployments.find { |d| d.status == 'PRIMARY' } task_arns = ecs.list_tasks(cluster: cluster, started_by: deployment.id).task_arns events = task_arns.flat_map do |arn| cwlogs.get_log_events( log_group_name: LOG_GROUP_NAME, log_stream_name: "#{LOG_STREAM_PREFIX}/#{CONTAINER}/#{arn.sub(/.+\//, '')}" ).events end events.sort_by(&:timestamp).each do |event| puts event.message end
現状では時間帯の指定等ができず大量のログが流れてきてしまうため、引き続き改善を行っています。
Docker imageの共通化をやめる
Dockerでは、言語環境やOSのパッケージなどの共通部分は、別Dockerfileに切り出してFROMで参照することによってfull build時間の短縮やイメージサイズの削減を図るのは常識であり、僕達もこのアプリのDockerfileはbase、development、productionの3つに分割していました。
具体的にbaseに含めているのは、以下に例として示す通り、developmentでもproductionでも共通のgemのインストールまでです。
FROM ruby:2.4.1-slim
RUN apt update && \
apt install --assume-yes \
make \
curl \
略
COPY package.json /app
COPY yarn.lock /app
RUN yarn install
COPY Gemfile Gemfile.lock /app
RUN bundle install --without development test
しかし、このような構成にしてしまった結果、gemを追加するのに一度container/base branchへmergeしてからでないとdevelopmentのコンテナでgemを使えなかったり、developmentにのみ含めたいOSパッケージの存在があったりして、少しやりすぎた共通化なのではないか、という認識がチーム内で発生しました。
なので、base imageは廃止し、productionでもdevelopmentでもFROMはruby公式のDocker imageを指定しています。これによる弊害は、今のところチーム内では認識できていません。
Docker imageのbuildが遅い
今までのDocker imageのbuild/pushは全てCircleCI 2.0にて行っていましたが、Docker layer cacheが効いたり効かなかったりして、buildに長時間かかることがしょっちゅうでした。そこで、layer cacheが有効になるように、CI serviceの乗り替えを検討しました。
Dockerを使用できるCI Serviceとして以下を検討しましたが、それぞれ記載する理由により採用を見送りました。
- Travis CI ( https://travis-ci.com/ )
- レイヤーキャッシュが使えない
- Codeship ( https://codeship.com/ )
- レイヤーキャッシュが使え実行自体も高速だが、各ステップの開始にひどいときは数分かかってしまう
- Codefresh ( https://codefresh.io/ )
- GitHub Integrationに未対応
次にオンプレミス環境で動作するCI Serviceを検討しました。それらに代表的なものとしてJenkinsとDrone.ioが挙げられるでしょう。
- Jenkins ( https://jenkins.io/ )
- Drone.io ( https://drone.io/ )
どちらも試用して検討し、上記理由からDrone.ioを採用しました。
Drone.ioはserverとagentに役割が分かれていて、agentをスケールさせることでbuild時間の短縮が目論めます。もちろん、Drone.ioもECR上に構築しました。
Drone.ioのserverとagent間の通信が切れる
drone-agentのみをスケールさせるために、drone-serverとdrone-agentは別Task Definition、別Serviceにしました。しかし、drone-agentからdrone-serverへのWebSockert通信がALBのIdle timeoutで強制的に切断されてしまい、この問題を解決することがどうしてもできませんでした。
なので、drone-serverとdrone-agent間の通信は、ALB越しではなく、インスタンスに割り当てられたPrivate IPによって行なうことにしました。弊害として、Dynamic Port Mappingを用いたdrone-serverのスケールアウトはできなくなりましたが、drone-serverをスケールアウトさせることに大した意味は無さそうなので、この構成で運用していこうと思います。
現時点のまとめ
- Rails 5.1 の新規社内アプリをECR上で運用している
- assetsはcontainerの中に含め、CDNから配信している
- NginxをRailsの前段に配置しているが、Rack middlewareに置き替えることを検討している
- developmentとproductionの共通部分をまとめたbase imageを採用していたが、廃止した
- CI ServiceをCircleCIからオンプレミスのDrone.ioに移行した
Docker化って、難しいですね。ログの解析やdb:migrateなど、今までの運用と大きく変更しなければならない部分だったり、思わぬ落し穴があったりして、インフラ構築の最中はずっとああでもない、こうでもない、どのような方法がいいか、もっといいやり方があるはずだ、と議論を重ねていました。とても面白かったです。
さて、僕のインフラチームとしての仕事はここまでで一旦終わり、今月からTMIXチームに復帰することになりました。今回の記事は、今までのインフラ部での仕事を振り返るために書いたというのが正直なところです。
TMIXでやっていくぞ!!!!!
DIST.16 「esa meetup in Tokyo〜情報共有Night」で発表してきました
こんにちは、CTOの赤松 aka ゆーけーです。
6月23日に開催された、DIST.16 「esa meetup in Tokyo〜情報共有Nightにて「サービス開発を加速させる情報共有」というタイトルで発表させて頂きました。
弊社では色々なesaの使い方をしていて、例えば私のesaの使い方とマーケティングチームやカスタムサポートチームでの使い方が結構違ったりします。
今回、DISTの沖さんから「サービス開発」というテーマを頂いていたので、私が今メインで携わっているSTEERSの開発でのesaの活用事例について話をしました。
DISTのイベントは初参加でしたが、沖さんの進行が上手で最後までスムーズでとてもよかったです。
本編も懇親会もたくさんの参加者がいらっしゃってとても楽しいイベントでした。今回登壇の機会を頂けたことをありがたく思います。
Tシャツを提供させて頂きました
STEERSからスピーカー様と参加者様のプレゼント用に10枚程度ですがTシャツを提供させて頂きました。
こちらSTEERSで購入可能ですので、よければお買い求めください。前回の名古屋でのTシャツも販売中です。
今後ともSTEERSをよろしくお願いいたします。
【全品送料無料】esa meetup in Tokyo ~情報共有Night 記念Tシャツ | オリジナルTシャツ販売 STEERS(ステアーズ)

【全品送料無料】esa meetup in Nagoya @ Misoca | オリジナルTシャツ販売 STEERS(ステアーズ)
発表の補足
発表内容については資料を見ていただくとして、当日発表後や懇親会などで質問頂いたりしたのでその辺について少しまとめてみようと思います。
中間成果物として書いた仕様は全部ストック記事に整理していますか?
していません。というのも、大体のことはコードなりでサービスそのものに実装されているので、出来上がっているモノ自体が仕様になるためです。
どちらかというと資料に書いたとおり、調べようとしてサクッとわからなかったらという感じで必要になったときにまとめることが多いです。他にも誰かから(例えばステークホルダーとか)質問されたときにも記事にしたりしています。
中間成果物に書いた仕様と実装をあわせるの大変じゃないですか?
基本的に中間成果物として書かれた仕様は「とっかかり」ぐらいのものです。開発するためにお互いの認識をある程度揃えるためのスタート地点的ぐらいのつもりで書いています。
なので、実際に実装に入ってしまえばあとはチャットだったりプルリクエストでのやりとりだったりします。ちょっとぐらい認識のズレがあってもそこで実装を修正してしまう感じですね。
もしかしたら「仕様」という言葉でちょっと重たく捉えた方もいるかもしれませんが、ノリ的にはホワイトボードでちょっと情報を共有するのとあまり変わりません。
今のところそれであまり混乱も起きていませんが、中間成果物の仕様と実装の食い違いで混乱があった場合はある程度中間成果物の仕様も更新したりする必要もあるかもしれません。
README使っていますか?
使っています。結構好きな機能ですね。カテゴリのREADMEはトップにあるREADMEより目立たないのがちょっと残念ですが、今のesaだとカテゴリをクリックしたときにそのカテゴリの記事一覧がでるので仕方ない気もします。
READMEには主にストック記事へのリンクをまとめています。どこどこのカテゴリにあるよというよりは、READMEにまとめてあるよの方がわかりやすいと思うので。
STEERSの場合だと、例えばTシャツの印刷位置・印刷サイズの大きさや、返品時の対応のルールといった業務上のことだったり、開発環境の構築といったような開発用ドキュメントへのリンクがはってあったりします。
他にもプロジェクトカテゴリの各施策で重たい施策ではREADMEを置いていたりします。施策の概要やチェックボックスで施策の進捗状況をメモしていたり、施策を進めるにあたって必要なドキュメントへのリンクや、打ち合わせなどで決まったことをまとめたりしています。
AWS CloudWatch Eventsをcronとして使う powered by maekawa

おはようございます。cronは「クーロン」と読むうなすけです。
実は2月頭からTMIX開発チームを離れ、インフラチームに所属しています。そして、インフラチームとしての初仕事として、AWS CloudWatch Eventsを用いたバッチ処理実行基盤の構築を行いました。
バッチ処理基盤の要件
Webサービスがある程度の規模に成長すると、一定の期間で定期的に実行するバッチ処理が必要になるでしょう。もちろんTMIXでもバッチ処理は必要で、それはアプリケーションサーバーのひとつにcronjobの実行を任せることで行っていました。
しかし、TMIXを将来Dockerで動かすことを考えると、いつ破棄されるか不明なコンテナでcronを実行させる訳にはいかず、この方法はいずれ使えなくなります。なにかしら別の方法を考える必要があります。
そして、次のような要件を定義しました。
処理自体は ECS Task で行う (MUST)
処理に関わる環境の構築について考えることを減らせるので、これは必須要件です。
実行ログ (MUST)
言わずもがな、これも必須要件です。
コードベースでの管理 (SHOULD)
Pull Requestを経由して、レビューを行ってからジョブの登録をしたいので、javan/whenever のようなDSLでも、もしくはcrontabそのものでも、とにかくジョブがコードで管理されている状態にしたいです。
マネージドサービスであること (SHOULD)
運用コストを削減したいからDocker化するのであって、ここで新たに管理対象が増えるのは避けたいところです。
ただ、ECSで運用できるのであればマネージドでなくてもよいことにしました。
実行時エラーを検知したい (SHOULD)
エラーが発生したことは何らかの方法で知る必要があります。
ワークフロー管理 (MAY)
cronサーバの代替なので、ワークフロー管理は必須ではありませんが、あれば言うことはないでしょう。
その他にもいくつかの要件がありましたが、大きなものは以上です。これらの要件を満たすかどうか、いくつかのジョブスケジューラーを比較・検討してみました。
検討したもの
kuroko2
cookpad/kuroko2 は、cookpadで開発されたジョブスケジューラ、ワークフローエンジンです。
kuroko2はよくできたジョブスケジューラですが、ジョブのコード管理ができず、ECS上で動かすことが困難であった(ように見えた)ので採用はしませんでした。
rundeck
rundeckは、オープンソースで開発されているジョブスケジューラで、有料のマネージドサービスもあります。
rundeckは公式なDockerfileが見当らず、マネージドサービスは高価すぎるので採用はしませんでした。
AWS Batch
AWS BatchはAWSが用意しているフルマネージドのバッチ処理基盤です。
AWS Batchはスケジュールに従って実行する機能がないこと、また僕が評価のために試用したときにいくら待ってもジョブが実行されずに評価不可能だったので採用しませんでした。
AWS CloudWatch Events
AWS ClowdWatch EventsはAWSが用意している、AWSのリソースの変化をトリガーとして様々な機能を呼び出すことのできるサービスです。
ClowdWatch Eventsは定期的、もしくはcron書式によるイベントを定義することができ、そこからAWS lambdaを経由してECS RunTaskを実行することができます。
しかし、コードによる管理は、それを行うツールが調べた限りでは存在しませんでした。
maekawaというCLI toolの開発
どのようなジョブが登録されているのか、どのようなジョブを登録しようとしているのかをPull Requestベースで管理したいので、 定義ファイルに従って状態を変更する、 codenize-tools/miam や codenize-tools/roadworker のようなべき等性を持つCLI toolが必要でした。
そこで、べき等性を持つ、CloudWatch Eventsを管理するCLI tool、maekawaを作成しました。
maekawaによって……
が可能になり、Pull Requestをベースとした、CIによるジョブスケジュールの定義が可能になりました。
maekawaは単なる社内ツールとしてではなく、OSSとして公開することにしました。また。個人的にチャレンジしたかったので、Golangで書いています。Golangで書いたことによって、CI環境へのセットアップが容易にできるようになったのは、予期しない利点でした。
全体的な処理の流れ
まず、cron書式などによって定義された時刻に、CloudWatch Eventsによってlambda functionが実行されます。lambda functionは、それ自体はECS RunTaskを実行するだけの薄い層として存在するだけです。lambdaを通じて実行されたECS Taskによって、目的のバッチ処理が実行される、という流れになっています。
なにに使用しているのか
こうして新しくなったバッチ処理基盤ですが、これで何を実行しているのかというと、現状は
- k1LoW/awspec の日次実行
- TMIXがSEOのためのタグを適切に設置できているかのチェッカ
- Amazon SES のbounce rate監視
などです。
今後、様々なジョブが登録されていくと思います。
以上、僕のインフラチーム移籍後の初仕事でした。今後ともTMIXならびにSTEERSをよろしくお願いします。